Rosetta is an ML experimentation framework for Named Entity Recognition on job postings. Built to benchmark transformer models on the SkillSpan dataset for extracting skills and knowledge entities from job descriptions.
Technical Highlights:
- Benchmarked 8+ models with a full automated evaluation harness
- Custom metrics: F1, per-class precision/recall, overfitting gap, inference latency, confusion patterns
- Best model: distilbert-base-uncased with 51% F1, 3.47ms inference latency, 66M params
- Near-zero overfitting gap (0.001) after 12.6 min training on CPU
Performance Comparison:
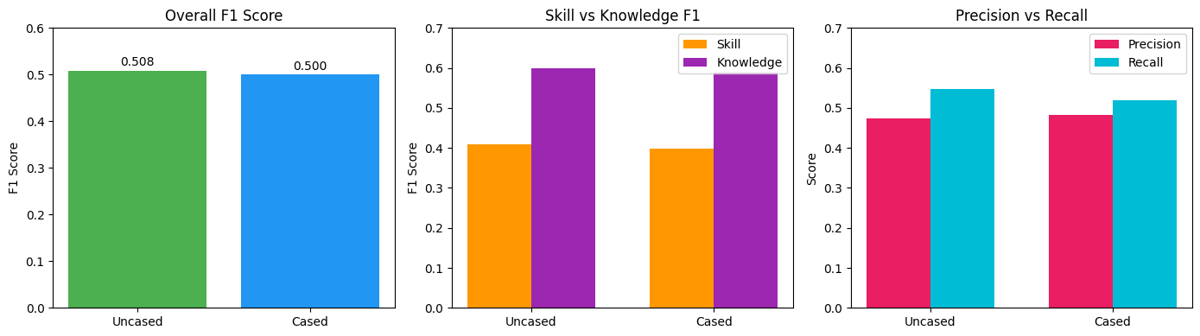
Key Findings:
- Knowledge entities easier to detect (F1 ~0.60) than Skills (F1 ~0.41)
- Root cause: Skills are multi-word phrases ("problem solving", "attention to detail") while knowledge entities are single tokens ("python", "javascript")
- Dominant error mode: I-Skill boundary confusion (missing span continuations)
- Uncased model has better recall (+2.8%), cased has slightly better precision
Overfitting Analysis:
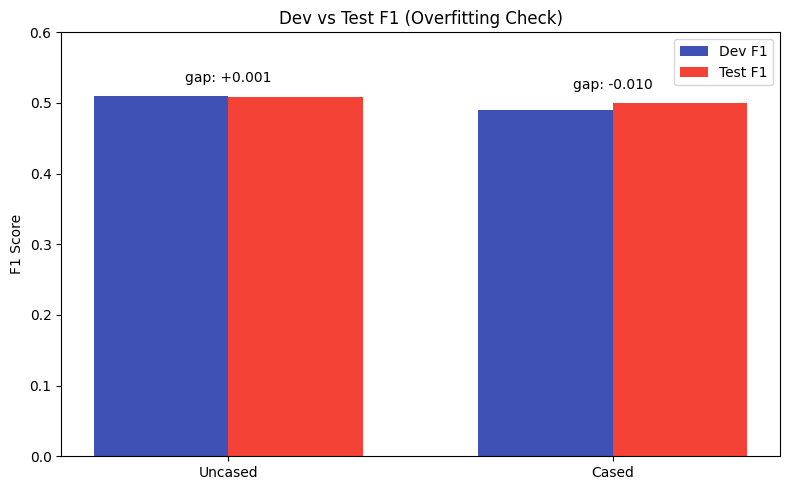
Both models show minimal overfitting (gap < 0.02)
Error Analysis:
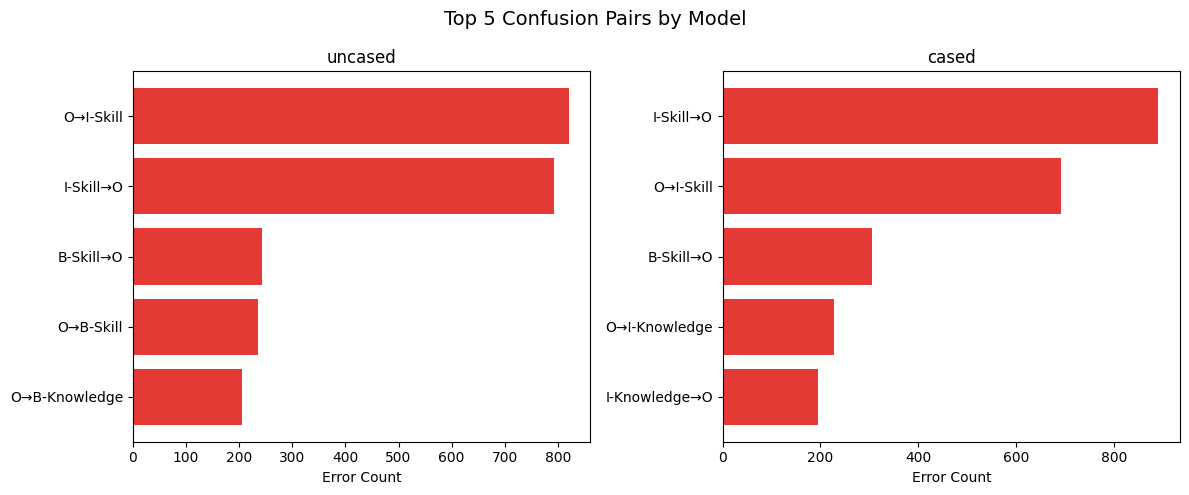
Top confusion pairs for distilbert-base-uncased:
- O → I-Skill: 820 errors
- I-Skill → O: 793 errors
- B-Skill → O: 243 errors
Production Pipeline:
Beyond benchmarking, the project includes a deployment pipeline (taxonomy.py) that runs the trained model against real job posting data (jacob-hugging-face/job-descriptions) with batched inference, chunking logic, and JSON output—a full loop from fine-tuning to production inference.
Built with Python, PyTorch, Transformers, and Hugging Face datasets.